+ 한국항공대학교 길현영 교수님의 컴퓨터구조론 과목 내용을 정리한 글입니다.
데이터 경로 (Data Path)
= CPU가 명령어 실행을 위해 데이터를 경유시키는 경로 (순서화된 단계)
- 데이터: 명령어 데이터, 명령어에 따른 피연산자 / 결과 데이터
ex) 세탁 시스템의 데이터(세탁물) 경로: 세탁 - 탈수 - 건조
< CPU가 명령어 실행을 위해 하는 일 >
1. 다음에 수행할 명령어(데이터) 주소를 계산한다. (연산장치, PC)
2. 데이터를 처리하기 위해 메모리에서 데이터를 읽거나 저장한다. (Read, Write)
3. CPU 내부의 고속 메모리인 레지스터 파일에 데이터를 일시적으로 보관하고, 연산장치를 통해 산술연산과 논리연산을 수행하고, 그 결과값을 레지스터 파일 / 연산장치에 보관한다.
< 데이터 경로의 기본 구성 요소 >
= 데이터 경로 상에 있는 HW 요소
=> PC, 레지스터 파일, ALU, 메모리 (+ 다양한 논리회로들: Shifter, MUX 등)
ISA 종류에 따라 다르고, 동일 ISA에서도 (HW적) 데이터 경로 구현은 다양하다.
=> picoMIPS의 데이터 경로에 대해 공부
데이터 경로 방식 (동기식)
1. 단일 사이클 방식 (초기)
하나의 명령어는 한 사이클 내에서 해당 명령어를 수행한다. (Clock Cycle)
- 하나의 명령어가 한 사이클 동안 전체 데이터 경로를 사용한다.
=> 명령어가 동일한 사이클동안 메모리나 ALU 등 HW 구성요소에 두 번 이상 접근/사용하는 것이 불가하다.
2. 다중 사이클 방식 (개선)
하나의 명령어가 다양한 개수의 사이클동안 해당 명령어를 수행한다. (한 개 이상)
명령어가 각 사이클마다 데이터 경로를 다시 사용이 가능하다.
=> 하나의 명령어는 어떤 HW 구성요소를 한 번 이상 사용이 가능하다.
< 정리 >
한 사이클에 데이터 경로를 한 번 사용할 수 있고 따라서, (해당 데이터 경로에 있는) HW 구성요소에 한 번 접근이 가능하다.
단일 사이클 방식은 하나의 명령어가 한 사이클을 사용하므로 데이터 경로를 한 번만 사용할 수 있고, HW 구성요소에 한 번만 접근할 수 있다.
다중 사이클 방식은 하나의 명령어가 다양한 개수의 사이클을 사용하므로 데이터 경로를 한 번 이상 사용할 수 있고, HW 구성요소에 한 번 이상 접근할 수 있다.

데이터 경로 방식에 따른 성능: 16bit 덧셈(Adder)
< 가정 >
CPU 실행 시간 = 명령어 개수 × 평균 CPI × 사이클 시간
1개의 FA 지연시간 = 1ns (Flipflop 지연 시간 무시)
1. 단일 사이클 방식 구현 (하드웨어적)
한 사이클 동안 16개의 FA(전가산기)를 사용하여 16개의 비트를 모두 더한다.
- 1 Cycle
- Cycle당 시간: 16 ns
- 실행 시간 = 명령어 1개 × 1 CPI × 16 ns = 16 ns
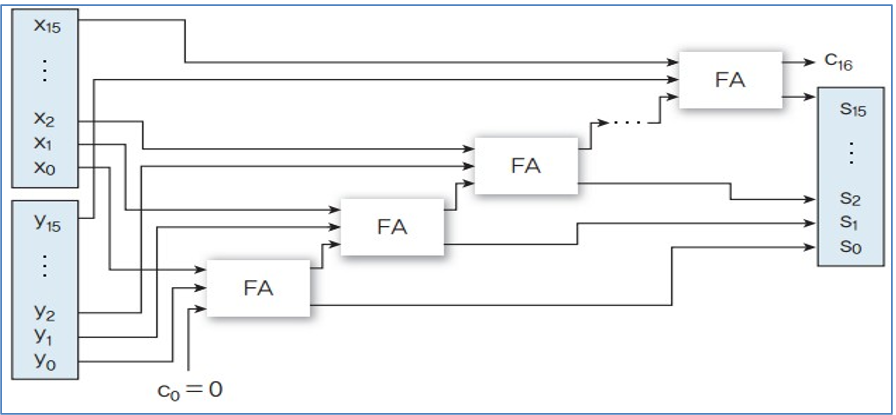
2. 다중 사이클 방식 구현 (소프트웨어적, Loop)
1개의 FA(전가산기)를 16번 반복 사용하여 1비트씩 연산하고, 그 결과를 차례로 저장한다.
(중간값을 저장하는 장치 Flipflop이 필요하다.)
- 16 Cycle
- Cycle당 시간: 1 ns
- 실행 시간 = 명령어 1개 × 1 CPI × 16 ns = 16 ns

즉, 실행시간은 같다.
그러나 다중 사이클 방식은 파이프라이닝을 사용할 수 있다.
picoMIPS 명령어 실행과 데이터 경로
picoMIPS 명령어 형식 (16 bit)
1. R-형식 명령어
=> 레지스터 2개를 사용하여 연산장치에서 처리한 결과를 다른 레지스터에 저장한다.
2. I-형식 명령어
=> 메모리 참조, 상수 피연산자를 가진 연산, 조건 분기 등을 수행한다.
3. J-형식 명령어
=> 무조건 분기를 수행한다.

picoMIPS 명령어 실행 단계
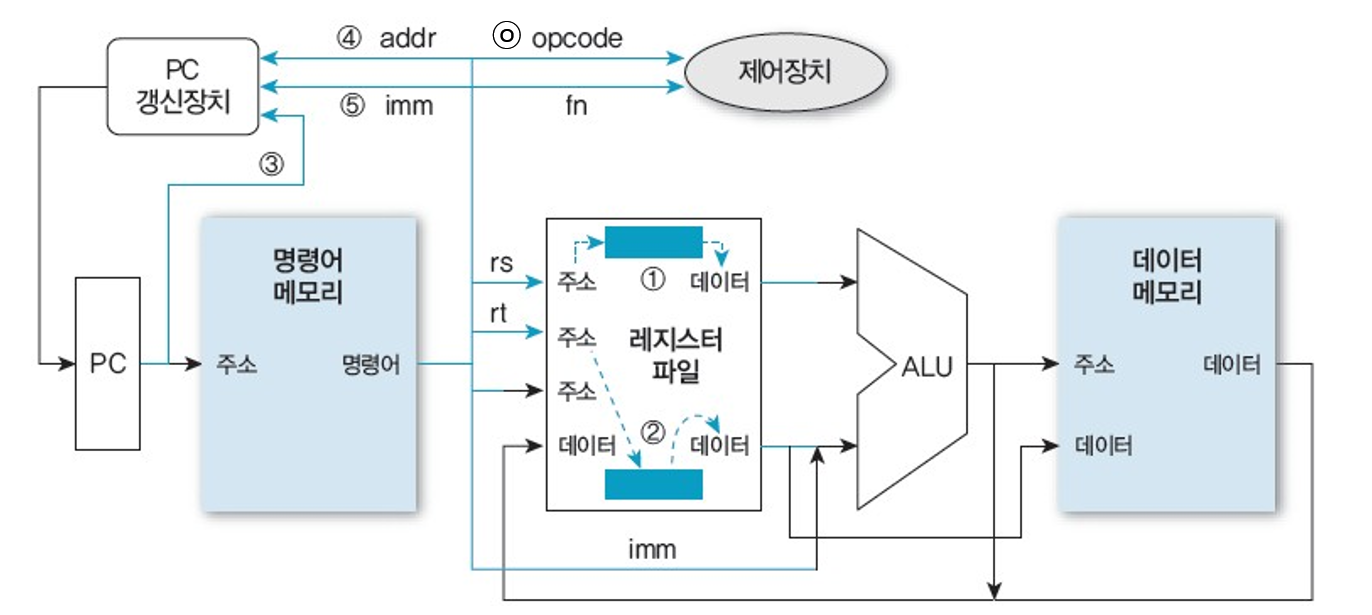
1. 명령어 인출 (모든 명령어 동일)
PC가 가리키는 메모리의 내용인 데이터(명령어)를 읽고, PC가 다음 명령어를 가리키도록 PC의 내용을 갱신한다. (명령어 길이만큼 증가)
2. 명령어 해독 및 레지스터 읽기 (명령어마다 약간의 차이 존재)
명령어의 연산 부호를 해독하고 필요한 레지스터 값을 읽는다.
- R-형식 명령어: 3개의 레지스터 주소를 추출하고, 그 중 2개의 레지스터 주소(rs, rt)를 이용하여 레지스터의 내용을 읽는다.
- I-형식 명령어: 2개의 레지스터 주소를 추출하고, 그 중 1개의 레지스터 주소(rs) 또는 2개의 레지스터 주소 (rs, rt)를 이용하여 레지스터 내용을 읽는다.
- J-형식 명령어: 레지스터의 내용을 읽을 필요 없다.
명령어 해독과 레지스터 읽기 과정은 병렬화가 가능하다.
=> 모두 R-형식 명령어로 간주하고, 명령어 해독을 하는 동안 2개의 레지스터 값을 읽는다. (동시에)
3. 명령어 기능 실행 (각 명령어마다 고유한 일 수행)
- 산술 및 논리 연산: ALU를 이용하여 연산을 수행한 후 결과를 레지스터에 저장한다.
- 메모리 참조: 메모리 주소를 계산하고, 메모리 - 레지스터 간 데이터를 이동시킨다. (Load 또는 Store)
- 조건 분기: 조건의 만족 여부에 따라 분기 주소로 PC를 갱신한다.
- 무조건 분기: PC를 조건 없이 분기 주소로 갱신한다.
+ IR에서 rt를 읽는 것은 위 경로, Reg[rt]에 쓰는 것은 아래 경로를 사용한다.
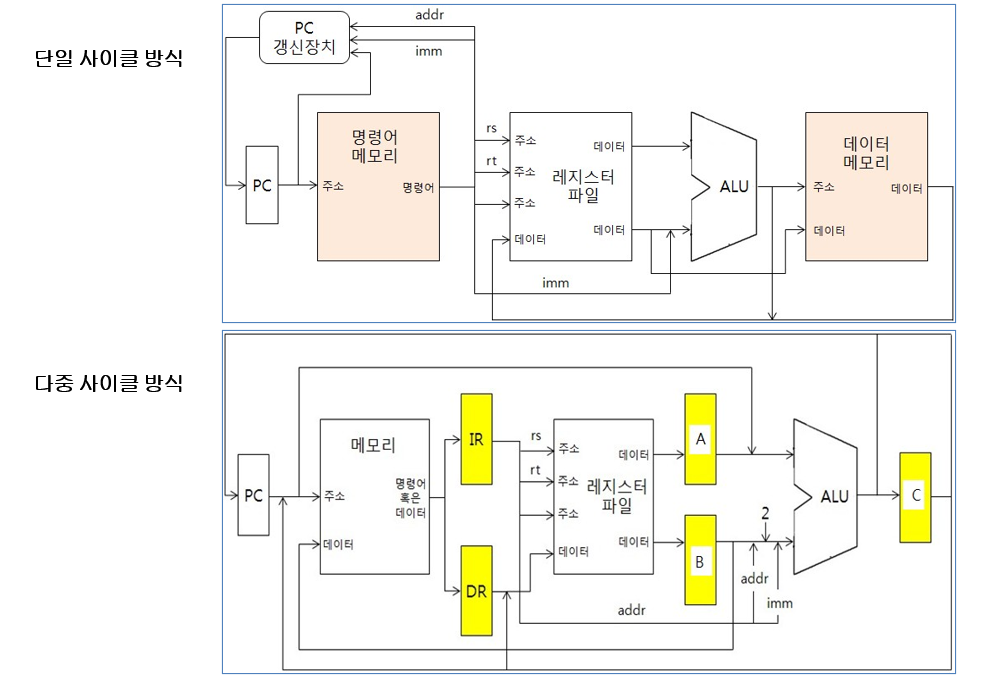
단일 사이클 방식 vs 다중 사이클 방식
단일 사이클 방식
명령어 실행에 필요한 세부 단계들(마이크로 연산)이 하나의 사이클 안에서 순서대로 수행된다.
데이터 경로에 한 번 접근할 수 있으므로, 명령어 메모리와 데이터 메모리 2개를 사용한다.
PC 갱신장치가 PC를 갱신한다.
다중 사이클 방식
다중 사이클 방식은 명령어에 따라 다양한 개수의 사이클을 사용할 수 있다.
- 명령어는 각 사이클 마다 데이터 경로를 다시 사용할 수 있다.
명령어 실행에 필요한 세부 단계들이 각기 다른 사이클에 수행된다.
ex) PC를 갱신하는 명령어 인출 과정과 ALU를 사용하는 명령어 고유 과정이 다른 사이클에서 수행 가능하기 때문에, 별도의 PC 갱신장치 없이 ALU를 사용하여 PC를 갱신한다.
데이터 경로에 여러 번 접근할 수 있으므로, 메모리를 1개 사용한다.
- 대신, IR과 DR을 두어 명령어인지, 데이터인지를 따로 저장한다.
데이터 계산 후 임시 저장소에 저장하여, 다음 단계에서 사용한다.
- 중간 결과값을 저장하는 FlipFlop이 필요하다.
=> 다중 사이클 방식은 파이프라이닝을 위한 작업이다.
파이프라이닝: 명령어의 데이터 경로를 세분화하고, 각기 다른 세부 단계를 동시에 수행하게 함으로써, 여러 명령어들을 중첩 수행 가능하도록 하여 성능을 향상시킨다.
단일 사이클 방식: 명령어 인출 단계
명령어 인출 (1)
= PC가 가리키는 메모리의 내용(M[PC])을 명령어로 인출한다.
현 단계에서 PC 갱신(다음 실행될 명령어 주소로 수정)은 불가하다.
- PC 갱신장치의 모든 입력(PC 자신 외에 addr 필드와 imm 필드)이 아직 준비되지 않았다.

단일 사이클 방식: 명령어 해독, 읽기 단계
명령어 해독 (0)
레지스터 읽기 (명령어를 해독하는 동안 동시 수행한다.)
- rs 필드와 rt 필드를 사용해서 레지스터 파일에 접근 (1, 2) 하고 해당 레지스터의 내용 Reg[rs]와 Reg[rt]를 읽는다.
PC 레지스터 (3), addr 필드 (4), imm 필드 (5)를 통해 다음 명령어의 주소를 계산할 수 있다.
- 아직 명령어의 종류를 모르기 때문에, 세 값을 먼저 모두 계산해놓고 PC 레지스터 갱신을 수행하지 않는다.
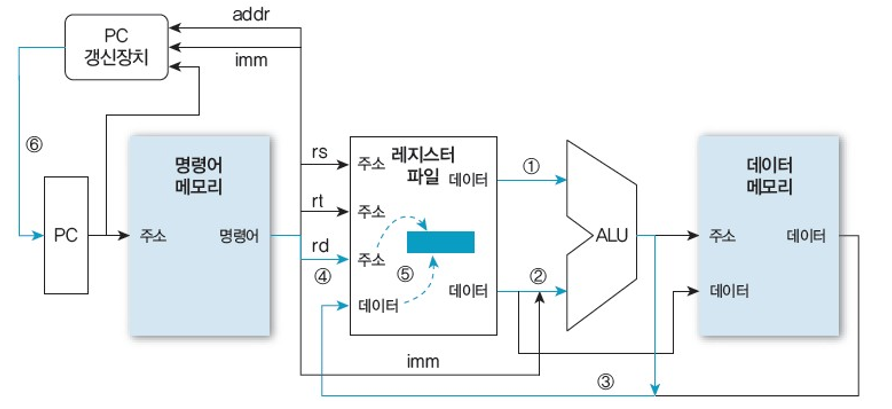
단일 사이클 방식: R- 형식 덧셈 명령어 실행 단계
2개의 레지스터 값을 ALU에서 처리한 후, 결과를 레지스터 파일에 기록한다.
ex) add $rd $rs $rt => $rd <- $rs + $rt
Reg[rs] (1)와 Reg[rt] (2)를 ALU에서 더한다.
덧셈 결과 (3)를 Reg[rd] (4)에 저장한다. (5)
그동안 PC 갱신장치에서 계산한 세 주소 중 순차적 실행을 위한 메모리 주소로 PC를 갱신한다. (6)
단일 사이클 방식: I- 형식 산술/논리 명령어 실행 단계
하나의 레지스터 값과 명령어에서 추출한 즉칫값(imm)을 ALU에서 연산하고 결과를 레지스터에 기록하는 명령이다.
ex) addi $rt $rs $imm => $rt <- $rs + imm
Reg[rs] (1)와 imm (2)을 ALU에서 덧셈 연산한다. (6bit의 즉칫값을 16bit로 부호 확장)
덧셈 연산 결과 (3)를 Reg[rt] (4)에 저장한다 (5).
그동안 PC 갱신장치에서 계산한 세 주소 중 순차적 실행을 위한 메모리 주소로 PC를 갱신한다. (6)

단일 사이클 방식: I- 형식 적재 명령어 실행 단계
적재: 메모리에 있는 데이터를 레지스터로 이동
Reg[rs]와 imm을 사용하여 메모리 주소를 계산하고, 이 메모리 주소 데이터를 읽어 Reg[rt]에 저장하는 명령이다.
ex) lw $rt imm($rs) => $rt <- M[$rs + imm × 2]
Reg[rs] (1)와 imm 필드 (2)을 사용하여 읽고자 하는 메모리의 주소 (3)를 계산한다.
- 6bit의 imm을 부호 확장하고, 1비트 L-Shift를 통해 word 주소를 메모리 byte 주소로 변환한다.
메모리에 접근하여 (4), 읽은 내용 (5)을 Reg[rt] (6)에 적재한다. (7)
그동안 PC 갱신장치에서 계산한 세 주소 중 순차적 실행을 위한 메모리 주소로 PC를 갱신한다. (8)

단일 사이클 방식: I- 형식 저장 명령어 실행 단계
저장: 레지스터에 있는 데이터를 메모리로 이동
Reg[rs]와 imm을 사용하여 메모리 주소를 계산하고, 이 메모리 주소에 Reg[rt]를 기록하는 명령이다.
ex) sw $rt imm($rs) => M[$rs + imm × 2] <- $rt
Reg[rs] (1)와 imm 필드 (2)을 사용하여 쓰고자 하는 메모리의 주소 (3)를 계산한다.
- 6bit의 imm을 부호 확장하고, 1비트 L-Shift를 통해 word 주소를 메모리 byte 주소로 변환한다.
Reg[rt] (4)를 계산해둔 메모리 주소 (3)가 지시하는 메모리에 저장한다. (5)
그동안 PC 갱신장치에서 계산한 세 주소 중 순차적 실행을 위한 메모리 주소로 PC를 갱신한다. (6)
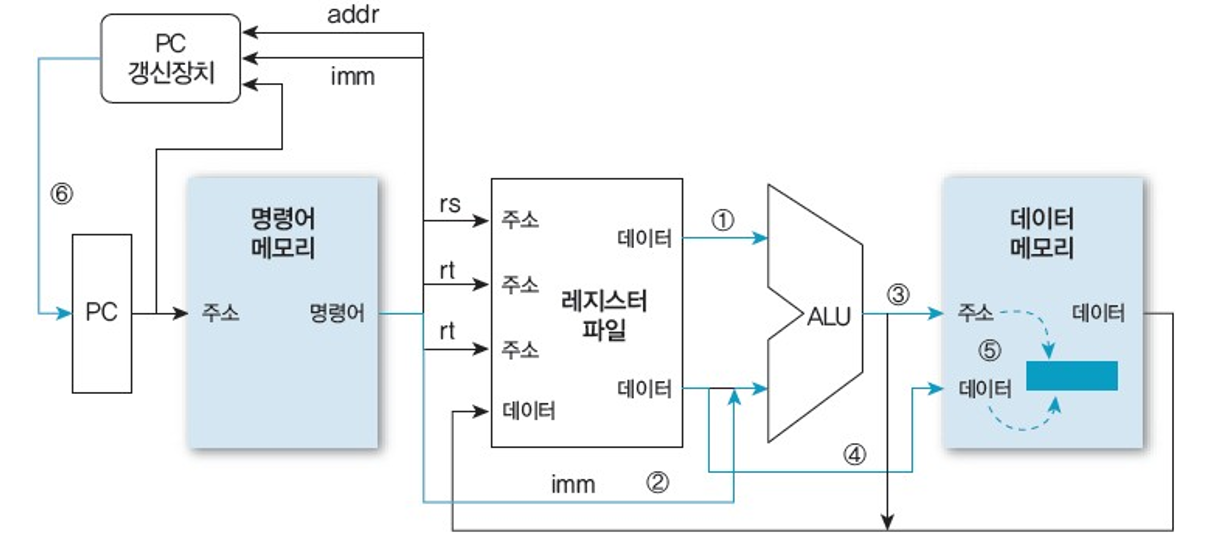
단일 사이클 방식: I- 형식 조건 분기 명령어 실행 단계
레지스터 2개의 내용을 비교한 후 조건을 만족하면 분기하는 명령이다.
ex) beq $rs $rt imm => if ($rs == $rt): PC <- PC + 2 + imm × 2
Reg[rs] - Reg[rt]를 수행한 후 (1), (2) 플래그 레지스터의 Z비트를 설정한다. (3)
Z 비트의 진위 여부(1 or 0)에 따라 PC를 갱신한다. (4)
- Z 비트가 참이면, PC 갱신장치에서 계산한 분기 주소 (PC + 2 + imm × 2)로 PC를 갱신한다.
- Z 비트가 거짓이면, 다음 명령어 주소 (PC + 2)로 PC를 갱신한다.

단일 사이클 방식의 J- 형식 무조건 분기 명령어 실행 단계
레지스터 비교없이 무조건 분기하는 명령이다.
ex) j addr => PC <- PC + 2 + addr × 2
레지스터 읽기 단계에서 계산한 무조건 분기 주소 (PC + 2 + addr × 2)로 PC를 갱신한다. (1)
+ 6bit imm 대신 12 bit addr를 사용한다.
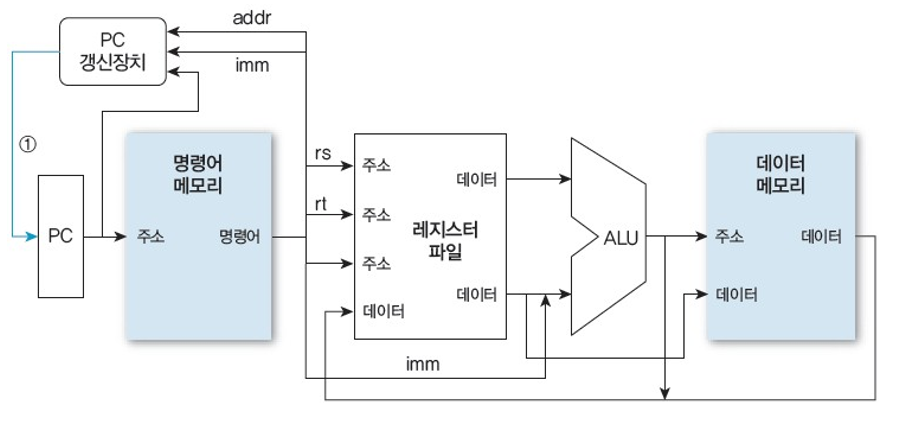
다중 사이클 방식: 명령어 인출 단계
PC (1)가 가리키는 메모리 주소의 내용, 즉 M[PC]에 저장된 명령어 (2)를 메모리에서 읽는다.
읽은 명령어를 명령어 레지스터 IR에 저장하여 (3) 다음 사이클에서 이용할 수 있게 한다.
PC (4)와 2 (5)를 ALU에 입력하고 더한 값으로 PC를 갱신한다. (6)
- 명령어 길이가 2byte이므로 순차적이라는 가정하에 PC를 PC + 2로 갱신한다.

다중 사이클 방식: 명령어 해독/읽기 단계
연산 부호 Opcode와 기능 필드 Fn을 제어장치에 보내 해독한다.
Reg[rs] (1)와 Reg[rt] (2)를 각각 임시 저장소인 A 버퍼와 B 버퍼에 저장한다. (3) (4)
PC (5)와 명령어의 imm 필드 (6)를 사용하여 조건 분기 명령을 위한 주소를 계산 후 C 버퍼에 저장한다. (7)
- 6 bit imm 필드의 부호를 확장하고, 워드 주소의 바이트 주소로 변환한다.

다중 사이클 방식: R- 형식 덧셈 명령어 실행 단계
ex) add $rd $rs $rt => $rd <- $rs + $rt
임시 저장소인 A 버퍼 (1)와 B 버퍼 (2)의 데이터를 덧셈한 후, 결과를 임시 저장소인 C 버퍼에 저장한다. (3)
- 해독 단계에서 R- 형식 명령어임이 밝혀졌으므로 이전에 C 버퍼에 저장된 값에 Overwrite한다.
C 버퍼에 저장된 연산 결과 (4)를 Reg[rd] (5)에 저장한다.
+ PC에는 이미 인출 단계에서 PC + 2를 저장했으므로 따로 작업할 필요가 없다.

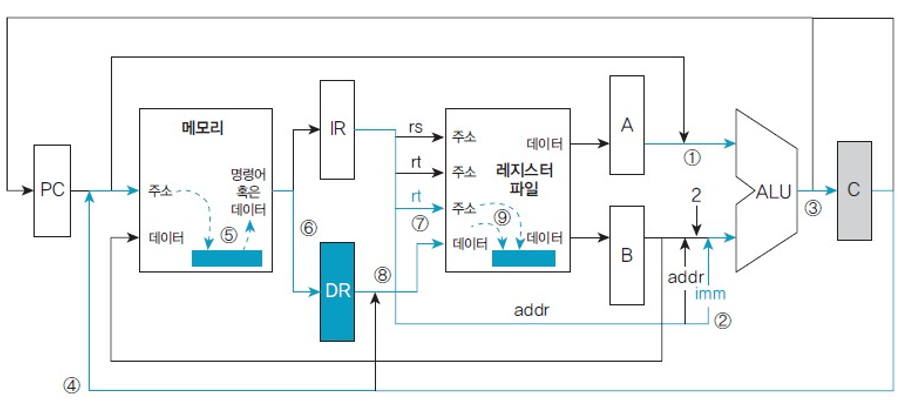
다중 사이클 방식: 적재 명령어 실행 단계
ex) lw $rt imm($rs) => $rt <- M[$rs + imm × 2]
Reg[rs]를 저장한 A 버퍼 데이터 (1)와 imm 필드 (2)를 사용하여 ALU에서 읽고자 하는 메모리 주소를 계산하고, 임시 저장소인 C 버퍼에 저장한다. (3)
- 6 bit imm 필드의 부호를 확장하고, 워드 주소의 바이트 주소로 변환한다.
C 버퍼에 있는 메모리 주소 (4)를 사용하여 메모리에 접근하고 (5) 읽은 내용을 임시 저장소인 데이터 레지스터 DR에 보관한다. (6)
Reg[rt] (7)를 사용하여 데이터 레지스터 DR이 보관 중인 데이터 (8)를 레지스터에 저장한다. (9)
데이터 경로 성능 비교 전 가정
가정 1. 지연 시간
메모리: 2ns
레지스터 파일: 1ns ( PC도 여기에 포함)
연산장치: 2ns
- 멀티플렉서, 부호확장기, 시프터 등은 구현 방식마다 다르므로 시간이 걸리지 않는 것으로 가정한다.
- 메모리의 쓰기와 읽기에 대한 지연 시간이 동일하다고 가정한다.
가정 2. 각 명령어 비율
R- 형식 연산 명령어: 44%
- 데이터 경로: 메모리 -> 레지스터 파일 -> 연산장치 -> 레지스터 파일
=> 단일 사이클 방식 지연시간 = 2ns + 1ns + 2ns + 1ns = 6ns
=> 다중 사이클 방식의 사이클 개수 = 4
적재 명령어: 24%
- 데이터 경로: 메모리 -> 레지스터 파일 -> 연산장치 -> 메모리 -> 레지스터 파일
=> 단일 사이클 방식 지연시간 = 2ns + 1ns + 2ns + 2ns+ 1ns = 8ns
=> 다중 사이클 방식의 사이클 개수 = 5
저장 명령어: 12%
- 데이터 경로: 메모리 -> 레지스터 파일 -> 연산장치 -> 메모리
=> 단일 사이클 방식 지연시간 = 2ns + 1ns + 2ns + 2ns = 7ns
=> 다중 사이클 방식의 사이클 개수 = 4
분기 명령어: 20%
- 데이터 경로: 메모리 -> 레지스터 파일 -> 연산장치 -> PC
=> 단일 사이클 방식 지연시간 = 2ns + 1ns + 2ns + 2ns = 6ns
=> 다중 사이클 방식의 사이클 개수 = 4
가정 3. 고정 사이클 시간을 사용
- 각 사이클이 동일한 시간을 사용한다. 즉, 모든 명령어가 동일한 클락 사이클 시간을 사용한다.
데이터 경로 성능
단일 사이클 방식
(평균) CPI = 1
- 단일 사이클 방식은 하나의 명령어를 수행하는 데 한 사이클(데이터 경로)을 사용하는 방식이다.
클락 사이클 시간 = 8ns
- 고정 사이클 시간을 사용하므로 모든 명령어를 하나의 클락 사이클을 사용해야하만다. 따라서 가장 긴 경로인 8ns가 클락 사이클 시간이 된다.
=> 명령어 당 CPU 실행 시간 = 1 × 8ns = 8ns
다중 사이클 방식
(평균) CPI = 0.44 × 4 + 0.24 ×5 + 0.12 × 4 + 0.2 × 4 = 4.24
- 명령어마다 다른 CPI를 사용하므로 필요한 사이클 개수가 다르다.
클락 사이클 시간 = 2ns
- 데이터 경로 부분에 따라 지연 시간이 각각 다르지만, 고정 사이클이므로, 가장 긴 부분 경로 시간인 2ns가 클락 사이클 시간이 된다.
=> 명령어 당 CPU 실행 시간 = 4.24 × 2ns = 8.48ns
위 과정에서는 단일 사이클 방식이 더 좋은 성능을 갖지만, 곱셉/나눗셈 같은 복잡한 연산은 단일 사이클 방식의 실행시간이 매우 증가할 수 있다.
또한 요즘 컴퓨터는 파이프라이닝의 사용을 위해 다중 사이클 방식을 더 사용한다.
'Computer Science > Computer Architecture' 카테고리의 다른 글
| [Computer Architecture] 해저드 (0) | 2023.11.18 |
|---|---|
| [Computer Architecture] 파이프라이닝 (1) | 2023.11.11 |
| [Computer Architecture] 데이터 연산 (picoMIPS) (1) | 2023.10.22 |
| [Computer Architecture] 디지털 논리 회로 (2) | 2023.10.22 |
| [Computer Architecture] 데이터 표현 (1) | 2023.10.15 |



